我们可以先将所有石头按照位置排序,然后计算每个石头移动到任意位置的费用,再利用前缀和的思想将这些费用累加起来。具体地,我们可以定义两个数组 pre[] 和 nex[],其中 pre[i] 表示前 i 个石头都移动到第 i 石头所在位置的总费用,nex[i] 表示第 i 个石头之后的所有石头都移动到第 i 个石头所在的位置的总费用。这样,对于石头,我们就可以在 O(1) 的时间内算出所有石头都移动到它的位置的总费用。
分析时间复杂度:排序算法时间复杂度为 O(nlogn),计算 pre 和 nex 的时间复杂度为 O(n),查找最小值的时间复杂度为 O(n),所以总时间复杂度为 O(nlogn)。
intmain(){ int t; cin >> t; for(int y=0;y<t;y++) { int n, k; cin >> n >> k;// 读取数组的长度 n 和选择的元素数量 k。 for (int i = 1; i <= n; i++) cin >> a[i];// 读取数组 a 的元素。 sort(a + 1, a + 1 + n);// 对数组 a 进行升序排序。 for (int i = 1; i <= n; i++){ prefix[i] = prefix[i - 1] + a[i];}// 计算数组 a 的前缀和,存储在数组 prefix 中
longlong ans = 0;
for (int i = 0; i <= k; i++) { longlong cha = (prefix[n - (k-i)] - prefix[2 * i]); // 计算选择了 k-i 个最大元素后,去掉了 2*i 个最小元素的情况下的和。 //中 i 表示已选择的最小元素的数量 ans = max(ans, cha); // 更新 ans,保存当前的最大和。 } cout << ans << endl; }
intmain(){ int n, m; cin >> n >> m; // 读入,数据不大用int int goods[n + 1] = {0};
vector<pair<int, int>> operate(m); for (int i = 0; i < m; i++) { int L, R; cin >> L >> R; operate[i] = make_pair(L, R); }
for (int i = 0; i < m; ++i) { goods[operate[i].first]++; if ((operate[i].second + 1) <= n) goods[operate[i].second + 1]--; }
int sum = 0, num = 0; for (int i = 0; i < m; ++i) { goods[operate[i].first]--; if ((operate[i].second + 1) <= n) goods[operate[i].second + 1]++; for (int i = 1; i <= n; ++i) { sum += goods[i]; if (sum ==0) num++; } cout << num << endl; sum = 0; num = 0; goods[operate[i].first]++; if ((operate[i].second + 1) <= n) goods[operate[i].second + 1]--; } return0; }
假设一个 n 边形 n 条边为 a1,a2,a3,...,an,定义该 n 边形的值 v=a1*a2*a3*...*an。定义两个 n 边形不同是指至少有一边的长度在一个 n 边形中有使用而另一个 n 边形没有用到,如 (3,4,5,6) 和 (3,5,4,6) 是两个相同的 n 边形,(3,4,5,6) 和 (4,5,6,7) 是两个不同的 n 边形。
现在有 t 和 n ,表示 t 个询问并且询问的是 n 边形,每个询问给定一个区间 [l,r],问有多少个 n 边形的值(要求所有边长度各不相同)在该区间范围内。
【输入输出描述】
输入格式:第一行包含两个正整数 t,n,表示有 t 个询问,询问的是 n 边形。接下来 t 行,每行有两个空格隔开的正整数 l, r ,表示询问区间 [l, r]。
1 2 3 4 5
43 110 3050 60200 200400
输出格式:输出共 t 行,第 i 行对应第 i 个查询的 n 边形个数。
1 2 3 4
0 1 18 32
对于所有评测用例:1<=t<=1e5, 3<=n<=10, 1<=l<=r<=1e5。
【题解】
本题我们采用搜索算法并使用剪枝优化。首先,由于有多次查询,我们不妨将所有乘积可能的情况都计算出来,从而方便最后的询问。由此,我们的搜索过程便是对于乘积进行搜索,而利用 DFS,我们得到的 n 元组是递增的,每一次搜索可以计算当前这个位置的上限,并记录当前所有边的乘积,因为乘的越多数字越大,当乘积大于 1e5 时直接返回。同时记录以下 n-1 条边的长度和 sum,最后一条边必须小于 sum。最后用前缀和快速求和查询。
#include<bits/stdc++.h> usingnamespace std; constint N = 1e5 + 10; int n; // 查找的是n边形 int cnt[N], prefix[N]; voidDFS(int dep, int st, int mul, int sum){ if (mul > 1e5) return; // 剪枝1:边乘积不大于1e5 if (dep == n + 1) { cnt[mul] += 1; return; }
int up = pow(1e5 / mul, 1.0 / (n + 1 - dep)) + 1; // 剪枝2:在对应乘积要求下下一条边的最大值
for (int i = st + 1; i < (dep == n ? min(sum, up) : up); i++) { DFS(dep + 1, i, mul * i, sum + i); } }
intmain(){ int t; cin >> t >> n; DFS(1, 0, 1, 0); for (int i = 1; i <= 1e5; i++) prefix[i] = prefix[i - 1] + cnt[i];
while (t--) { int l, r; cin >> l >> r; cout << prefix[r] - prefix[l - 1] << endl; } return0; }
【2】串变换
【题目描述】
有两个长度为 n 的数字字符串 S 和 T。一共有 k 个操作,操作只可能是以下两种类型:
1 x v 表示将 S[x] 变为 (S[x] + v) % 10;
2 x y 表示交换 S[x] 和 S[y]。
你可以挑选出任意个操作,以任意顺序执行,但是每个操作最多只能执行一次,如果可以将 S 串变为 T 串,则输出 Yes,反之输出 No。
【输入输出描述】
输入格式:第一行输入一个正整数 n,表示字符串 S 和 T 的长度。第二行输入一个长度为 n 只由数字构成的字符串 S。第三行输入一个长度为 n 只由数字构成的字符串 T。第四行输入一个正整数 k,表示操作的数量。接下来 k 行,每行三个整数,其中第 i 行表示第 i 种操作的三个参数 op[i], x[i], y[i]。
1 2 3 4 5 6 7
5 01012 10103 3 201 232 141
输出格式:一行一个字符串,如果通过操作可以使 S 串和 T 串相等,则输出 Yes,反之则输出 No。
// 全局变量 int n, m, res, a[N], b[N]; // n 和 m 分别表示两个图的节点数,res 用于存储最大匹配深度, // a 和 b 分别存储两个图的节点标记 vector<int> G1[N], G2[N]; // G1 和 G2 分别存储两个图的邻接表
// 深度优先搜索函数 // 因为是树,不用考虑除父结点之外的回溯情况 voiddfs(int u1, int far1, int u2, int far2, int dep){ res = max(res, dep); // 更新最大匹配深度
// 使用哈希表存储第一个图中当前节点的邻接节点及其标记 map<int, int> mp; for (auto v : G1[u1]) { // 遍历第一个图中当前节点 u1 的邻接节点 if (v == far1) continue; // 跳过父节点(避免回溯) mp[a[v]] = v; // 将邻接节点的标记存储到哈希表中 }
// 遍历第二个图中当前节点 u2 的邻接节点 for (auto v : G2[u2]) { if (v == far2) continue; // 跳过父节点(避免回溯) // 如果第二个图的邻接节点标记在第一个图的哈希表中存在 if (mp[b[v]]) { dfs(mp[b[v]], u1, v, u2, dep + 1); // 递归搜索,深度加1 } } }
intmain(){ cin >> n >> m; // 输入两个图的节点数 for (int i = 1; i <= n; i++) cin >> a[i]; // 输入第一个图的节点标记 for (int i = 1; i <= m; i++) cin >> b[i]; // 输入第二个图的节点标记
// 输入第一个图的边 for (int i = 2; i <= n; i++) { int u, v; cin >> u >> v; G1[u].push_back(v); // 添加边 G1[v].push_back(u); // 添加边(无向图) }
// 输入第二个图的边 for (int i = 2; i <= m; i++) { int u, v; cin >> u >> v; G2[u].push_back(v); // 添加边 G2[v].push_back(u); // 添加边(无向图) }
boolkmp(string s, string t){ int n = s.length(), m = t.length(); vector<int> next(m);
int idx = 0; for (int i = 1; i < m; ++i) { while (idx && t[i] != t[idx]) { idx = next[idx - 1]; } if (t[i] == t[idx]) { idx++; } next[i] = idx; }
idx = 0; for (int i = 0; i < n; i++) { while (idx && s[i] != t[idx]) { idx = next[idx - 1]; } if (t[idx] == s[i]) { idx++; } if (idx == m) returntrue; }
returnfalse; }
intmain(){ int n, m, k; cin >> n >> m >> k; string s, t; cin >> s >> t; vector<string> f; for (int i = 0; i < n + 1 - k; ++i) { f.push_back(s.substr(i, k)); } int len = f.size(); bool valid = false; for (int i = 0; i < len; ++i) { for (int j = i + k; j < len; ++j) { string x = f[i] + f[j]; if (kmp(x,t)) { valid = true; break; } } }
if (valid) cout << "Yes"; else cout << "No";
return0; }
第六章 · 数学
第七章 · 数据结构
第八章 · 图论
【1】寻找图中是否存在路径
【题目描述】
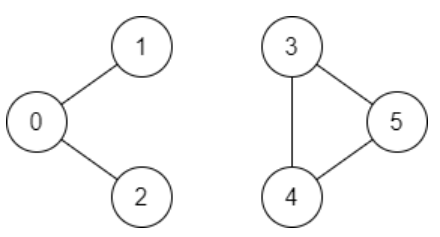
有一个具有 n 个顶点的 双向 图,其中每个顶点标记从 0 到 n - 1(包含 0 和 n - 1)。图中的边用一个二维整数数组 edges 表示,其中 edges[i] = [ui, vi] 表示顶点 ui 和顶点 vi 之间的双向边。 每个顶点对由 最多一条 边连接,并且没有顶点存在与自身相连的边。
classSolution { public: booldfs(int source, int destination, vector<vector<int>> &adj, vector<bool> &visited){ if (source == destination) { returntrue; } visited[source] = true; for (int next : adj[source]) { if (!visited[next] && dfs(next, destination, adj, visited)) { returntrue; } } returnfalse; }
boolvalidPath(int n, vector<vector<int>>& edges, int source, int destination){ vector<vector<int>> adj(n); for (auto &edge : edges) { int x = edge[0], y = edge[1]; adj[x].emplace_back(y); adj[y].emplace_back(x); } vector<bool> visited(n, false); returndfs(source, destination, adj, visited); } };
【2】所有可能的路径
【题目描述】
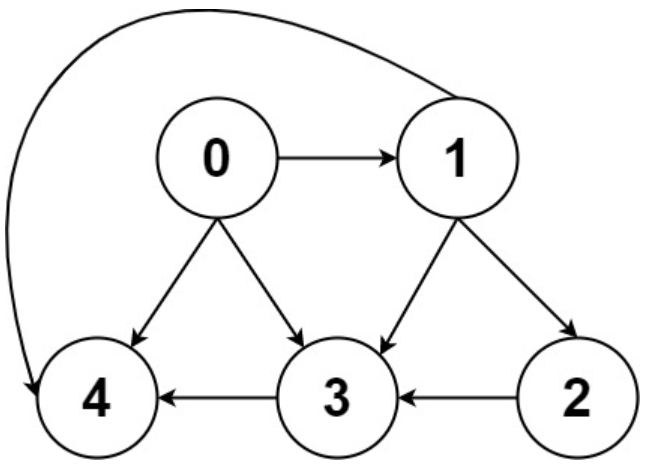
给你一个有 n 个节点的 有向无环图(DAG),请你找出所有从节点 0 到节点 n-1 的路径并输出(不要求按特定顺序)
graph[i] 是一个从节点 i 可以访问的所有节点的列表(即从节点 i 到节点 graph[i][j]存在一条有向边)。